What is a Cache? Link to heading
A cache is a secondary data store that’s faster to read from than the data’s primary store. The purpose of a cache is to improve application performance by:
- Reducing network calls to the primary data store: Instead of repeatedly querying the database, the cache handles data retrieval, offloading processing from the database. This reduces database connection consumption, often a limiting factor, and allows the database to perform faster.
- Increasing performance: Data in a cache is typically stored in random-access memory (RAM), providing quicker access than querying a database.
In distributed databases, the performance enhancement might be marginal due to network call latency, but the increase in scalability can be significant.
Caching Patterns Link to heading
Standard Read/Write Link to heading

Read Operation: Link to heading
- The service attempts to fetch an item from the cache.
- If the item is not found, it queries the database.
- Once retrieved, the item is added to the cache.
- The service returns the item to the user.
Write Operation: Link to heading
- The service removes the item from the database.
- The service then removes the item from the cache.
- The service returns a success response to the user.
These steps keep the cache and database in sync, though they are separate transactions.
Read-Through Link to heading
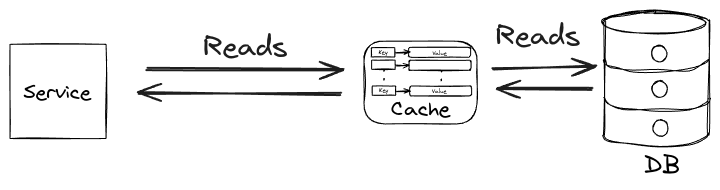
Read-through caching modifies the standard read process by making the cache responsible for database queries:
- The service checks the cache for the requested item.
- If the item is not in the cache, it queries the database.
- The item is retrieved and added to the cache.
- The cache returns the item to the service, which passes it to the user.
The service only interacts with the cache, which handles all database operations.
Write-Through Link to heading
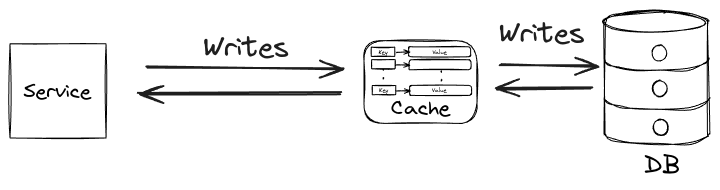
Write-through caching modifies the standard write process by delegating database updates to the cache:
- The service removes the item from the cache.
- The cache then removes the item from the database.
- The service only interacts with the cache, which handles database operations.
This approach simplifies the service logic by allowing it to view the cache as the primary data store.
Write-Behind (Write-Back) Link to heading
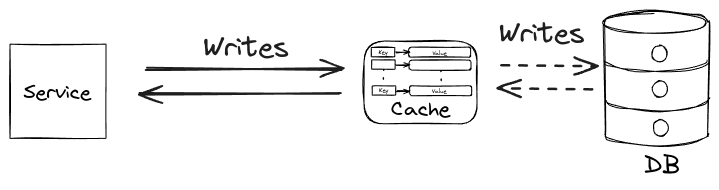
In a write-behind setup:
- The service removes the item from the cache.
- The cache immediately returns a success response to the service.
- Asynchronously, the cache updates the database in the background.
While this offers high performance and responsiveness, it introduces risks such as complex error handling and potential data inconsistencies.
Caching Topologies Link to heading
Traditional Isolated In-Memory Cache Link to heading
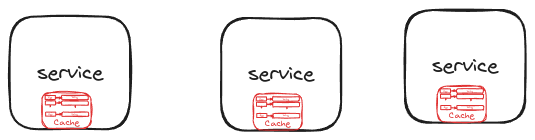
A traditional single in-memory cache stores data in the memory of an application instance, allowing for fast data retrieval. This approach works well in monolithic applications, reducing database load and speeding up response times.
However, in a microservices architecture, where multiple instances of the same service may run simultaneously, each instance may maintain its own local cache. This can lead to issues such as:
-
Inconsistent Response Times:
- Example: In an orders service with multiple instances, if instance 1 has all order items cached, requests to instance 1 will be fast. But if instance 3 has an empty cache, it will query the database, leading to slower response times. This inconsistency can frustrate users.
-
Cache Inconsistency:
- Example: If an order is removed and the removal request hits instance 1, it will remove the item from its cache and the database. However, instance 3, which has the item cached, will still show the item, leading to outdated or incorrect data being presented to users.
Despite these challenges, a single in-memory cache is useful for data that doesn’t change frequently, such as configuration values, code lookups, or read-only data.
Embedded (Replicated) Cache Link to heading
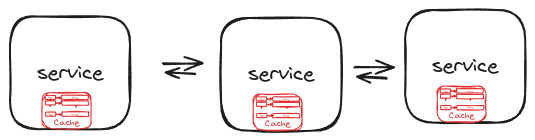 In embedded mode, the application and the cache share the same memory space. Each application instance has its own cache, synchronized with others to ensure consistency. This approach eliminates the need for an external cache server, reducing latency for cache reads and writes. However, large caches can cause memory issues, making embedded caching suitable for smaller datasets.
In embedded mode, the application and the cache share the same memory space. Each application instance has its own cache, synchronized with others to ensure consistency. This approach eliminates the need for an external cache server, reducing latency for cache reads and writes. However, large caches can cause memory issues, making embedded caching suitable for smaller datasets.
Distributed (Client-Server) Cache Link to heading
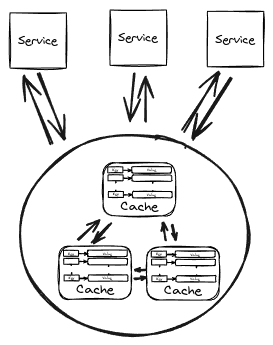
In the distributed topology, the cache is separated from the application, running on dedicated servers. Applications connect to these cache nodes through clients. This allows the cache cluster to scale independently, suitable for applications with large datasets and high availability requirements. However, this approach can introduce higher latency due to network requests and depends on the external cache servers’ availability.
Near Cache Hybrid Link to heading
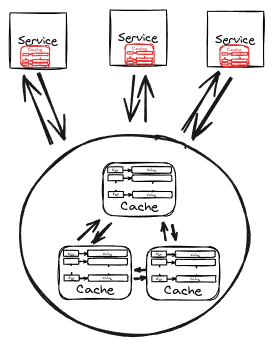
The near cache hybrid topology combines embedded and distributed caches. It uses a local cache on the client side and a distributed cache on the server side. The client-side cache stores frequently accessed data locally, reducing the need for network requests. This approach reduces latency and improves performance, combining the scalability of a distributed cache with the performance benefits of a local cache.
Performance and Fault Tolerance Considerations Link to heading
Performance varies among topologies. Replicated caches offer the fastest access, distributed caches have higher latency due to network requests, and near cache hybrid varies depending on synchronization needs. Fault tolerance also differs: replicated caches are highly fault-tolerant, distributed caches depend on external servers, and near cache hybrid requires careful synchronization for data consistency.
Update rates are another consideration. Replicated caches suit low update rates, distributed caches handle high update rates better, and near cache hybrid works well with relatively low update rates.