Kafka is an event streaming platform designed to handle massive volumes of real-time data efficiently. At its core lies a distributed storage system built for scalability, ensuring it can seamlessly accommodate ever-growing data demands.
This distributed nature allows Kafka to function as a cluster of machines, each playing a role in storing the data stream. This approach offers significant advantages:
- Scalability: As data volumes increase, additional nodes can be added to the cluster, effectively distributing the storage burden and ensuring smooth operation.
- Fault Tolerance: If a node fails, the data remains accessible because it’s replicated across multiple nodes. This redundancy guarantees high availability and protects against data loss.
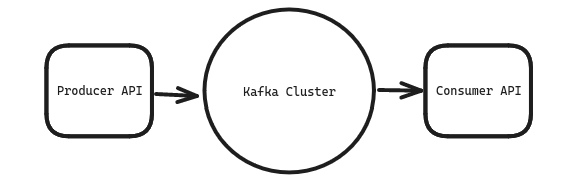
Data flows through Kafka using a publish-subscribe model centered around two key APIs:
- Producer API: This API acts as the entry point for data. Producers, which can be any application or service, publish streams of events (messages) into designated categories called topics.
- Consumer API: On the receiving end, the Consumer API empowers applications to subscribe to specific topics of interest. Consumers continuously listen for new events published to their subscribed topics and process them accordingly.
Events Link to heading
At the heart of Apache Kafka lies the concept of events. These events act as the lifeblood of the platform, representing anything that happens within your system. A user logs in, a sensor transmits a reading, a product gets purchased – all of these are captured as events in Kafka.
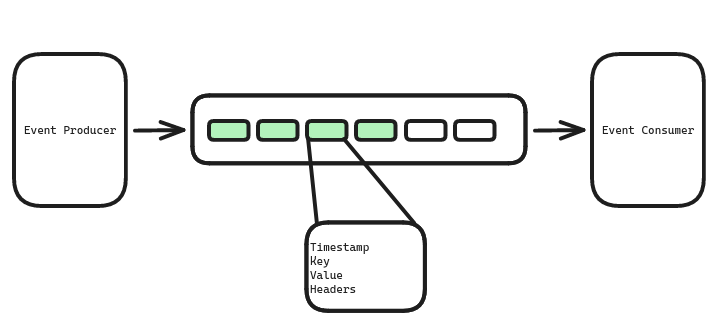
Each event finds its home in a structure called a record. Think of a record as a capsule holding the details of the event. Inside this capsule, you’ll find:
- Timestamp: A precise record of the exact moment the event occurred, ensuring a clear timeline of happenings.
- Key: This multi-talented element serves several purposes. It can dictate the order in which events are processed, ensuring a sequential flow if needed. The key can also group related events together, enabling efficient processing. Additionally, it can even influence how long data is retained within Kafka.
- Value: The heart of the event, the value field carries the actual payload. This is where the “what” of the event resides, often containing serialized data in formats like JSON, Avro, or Protocol Buffers for compactness and efficiency.
- Headers (optional): For those events requiring extra details, headers provide a space to store additional metadata, enriching the context of the event.
But Kafka doesn’t restrict you to rigid data formats. Both the key and value fields are stored as flexible byte arrays. This grants you the freedom to choose your preferred serialization method for the event data. Whether you favor JSON’s human-readable nature, Avro’s compact efficiency, or Protocol Buffers’ language-agnostic approach, Kafka adapts to your preference.
Topics Link to heading
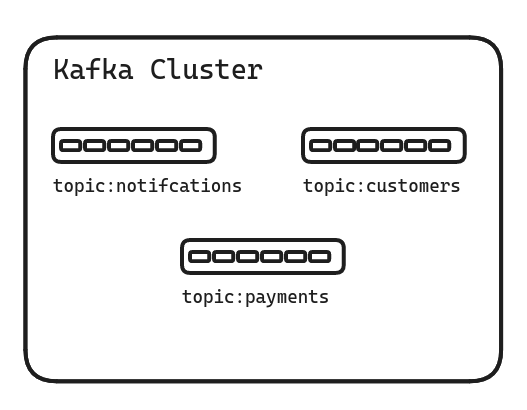
Kafka topics function similarly to database tables, but for event streams.
Grouping Events: A topic acts as a category, holding events of the same type. Just like a table stores data relevant to a single subject (e.g., customers in a “Customers” table), a topic groups events with a common theme (e.g., purchase confirmations in a “Purchases” topic).
Publishing Events: When you generate events, you specify the topic they belong to. This ensures events are delivered to the intended category within the Kafka cluster.
Subscribing to Events: Consumers (applications that read events) specify the topics they’re interested in. They only receive events published to those specific topics, streamlining data flow.
Immutable Events: Once published to a topic, events cannot be changed. This maintains data integrity and ensures everyone accessing the stream sees the same consistent sequence of events.
Distributed Storage: As a distributed system, Kafka spreads topic data across various storage nodes within the cluster. This approach ensures scalability and fault tolerance – even if a node fails, the data remains accessible on other nodes.
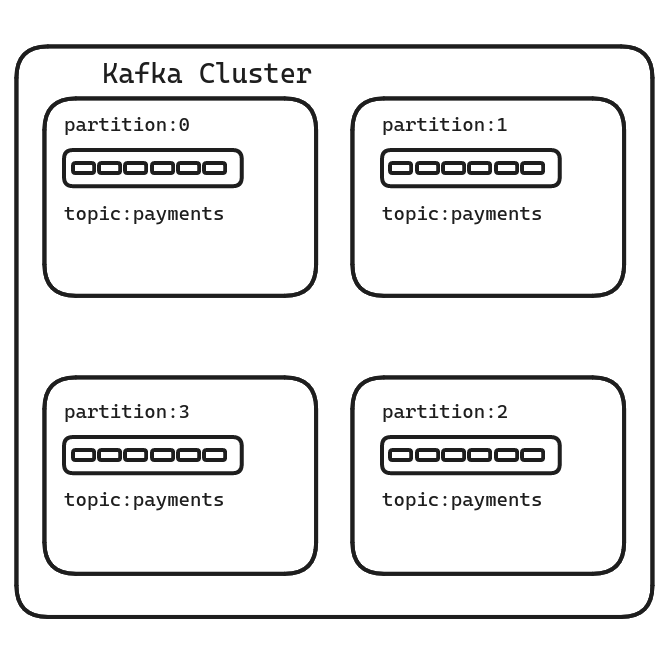
Partitions Link to heading
Partitions are the workhorses behind scalability and parallelism. They act as the fundamental unit of parallelism within a topic, allowing for efficient processing of high-volume event streams. Imagine a Kafka topic as a large stream of messages. To manage this stream effectively, Kafka divides it into smaller, ordered sequences of messages called partitions. Each partition is essentially a log file that resides on a single node (broker) within the Kafka cluster. When you create a topic, you specify the number of partitions. This is a crucial decision that impacts performance and scalability. A higher number of partitions enables greater parallelism, but can also increase management overhead.
Benefits of Partitions:
- Scalability: By distributing data across multiple nodes, partitions allow Kafka to handle large volumes of event traffic. Each broker can handle its assigned partitions independently, reducing the load on any single node.
- Parallelism: Producers can write to different partitions concurrently, significantly improving write throughput. Similarly, consumers can subscribe to individual partitions and process messages in parallel, enhancing read performance.
Accessing Partitions:
Producers: While each partition resides on a single node, producers can distribute events among partitions for parallel processing. This can be done using a round-robin approach or by a custom partitioning strategy based on message keys or other attributes.
Consumers: Consumers subscribe to specific partitions within a topic, allowing them to focus on a particular subset of the event stream. This can be beneficial for:
- Ordered Processing: If message order within a partition is crucial, consumers can subscribe to specific partitions and process messages sequentially.
- Load Balancing: Consumers can be assigned partitions across different nodes to distribute the processing load evenly across the cluster.
Number of Partitions: The optimal number of partitions depends on factors like message volume, desired throughput, and consumer processing capabilities. It’s generally recommended to have at least as many partitions as the number of consumer instances to ensure parallelism.
Partitioning Strategy: For scenarios where message order within a specific category is important, consider using a partitioning strategy based on message keys. This ensures that messages with the same key always land in the same partition, preserving order.
Offsets Link to heading
Kafka partitions, as we’ve explored, are the workhorses behind scalability and parallelism. But their power goes beyond just dividing data. Each partition introduces a companion concept called offsets, creating a dynamic duo for managing event streams.
Think of a Kafka partition as a continuously growing log. Each event within this log has a unique identifier, the offset, acting like a fingerprint. Starting at 0 for the first message, offsets increment sequentially for each subsequent addition. This offset pinpoints the exact location of an event within the ordered sequence of the partition.
Offsets empower consumer functionality in several ways:
- Tracking Progress: Consumers maintain their own offsets for subscribed partitions. This offset reflects the last processed message. When resuming, the consumer picks up from the stored offset, ensuring no messages are missed.
- Restarting: Consumer crashes are inevitable. Thanks to offsets, consumers can resume processing from the last known offset, eliminating the risk of missing or reprocessing messages.
- Parallel Processing: Offsets unlock the true potential of parallel processing in Kafka. Multiple consumers can subscribe to the same topic and process different partitions (or even the same partition) concurrently. Each consumer keeps track of its own offsets, guaranteeing efficient and independent processing across the cluster.