Setting the Stage for Distributed Storage Link to heading
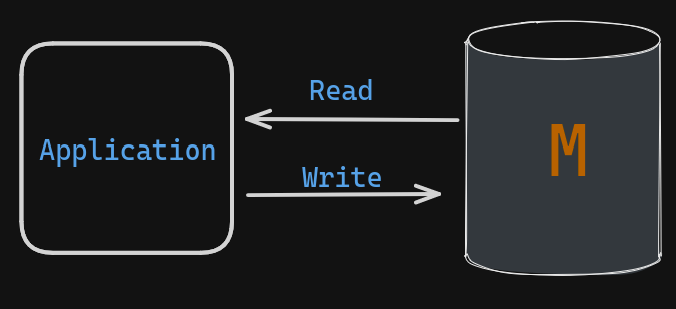
Non-distributed Storage (Single-Master System):
Imagine your favorite local coffee shop. Keeping track of customer preferences on a simple notepad (single-server database) is a breeze. New entries are readily added, and the system is clear-cut. However, as the shop’s popularity explodes, the notepad becomes a bottleneck.
Read Replication Link to heading
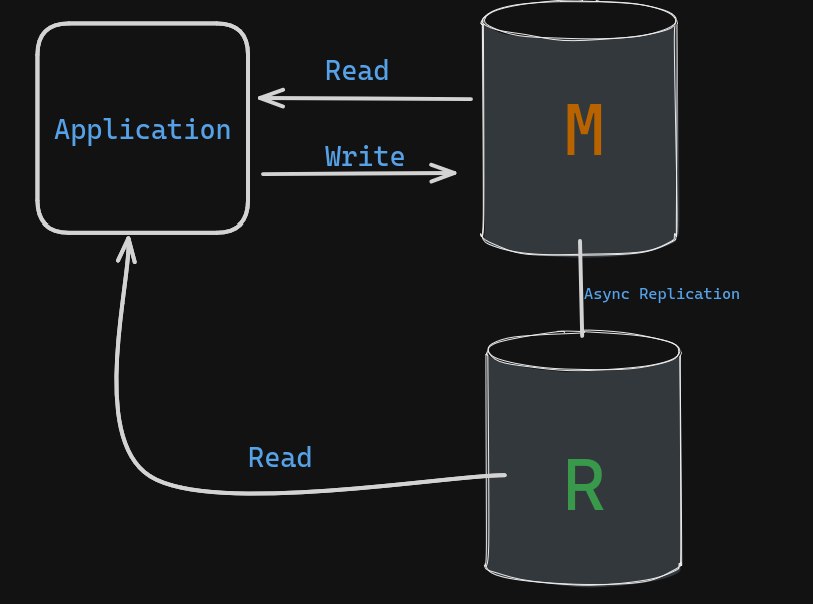 Read Replication:
Read Replication:
- The coffee shop thrives and attracts more customers.
- To handle the increased workload, the barista team expands.
- The single pad of paper (master database) is replicated for the new baristas (read replicas).
- The head barista (master) updates the original pad, then copies the changes to the replicas (asynchronously).
Benefits:
- Scales read traffic: Customers can be served faster by multiple baristas (read replicas) accessing customer preferences.
Drawbacks:
- Eventual Consistency: Updates might not be immediately reflected on all copies. Ordering a new favorite drink might not be available to all baristas right away.
- Increased Complexity: Managing and maintaining multiple copies introduces operational overhead.
- Limited for Write-Heavy Workloads: Read replication is not ideal for scenarios with frequent updates (writes).
Sharidng Link to heading
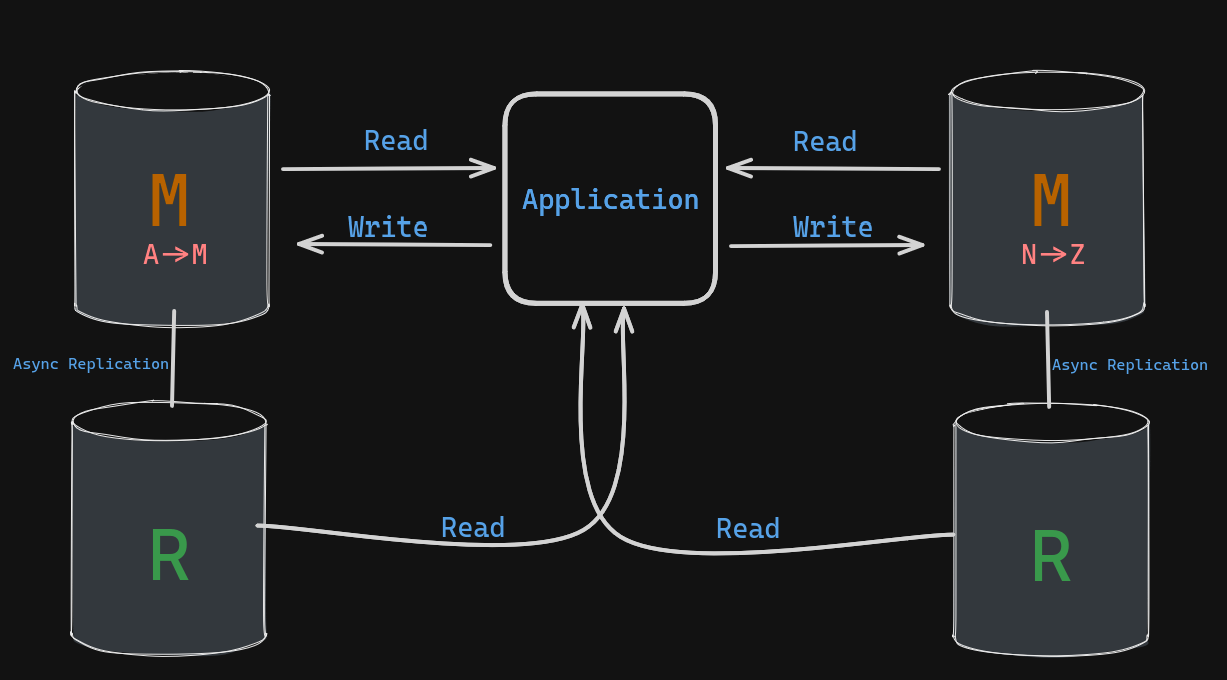
Sharding for Scalability:
- Read replication becomes insufficient for a highly popular coffee shop (heavy write workload).
- A single head barista updating all favorite drinks creates a bottleneck.
Sharding Approach:
- Sharding distributes the workload by splitting the data based on a key (customer name).
- Two head baristas (shards) are responsible for different name ranges (alphabetical).
- Each shard maintains its own read replica set for scalability.
Benefits:
- Increases write throughput by distributing updates across multiple shards.
Drawbacks:
- Increased Complexity: Clients need to know which shard to access for their data (routing).
- Limited Data Model: Sharding works best with data models where every query has a common key.
- Limited Data Access Patterns: Complex queries that span multiple shards require gathering data from all shards (scatter-gather), reducing efficiency.
Reference Link to heading
Distributed Systems in One Lesson by Tim Berglund: https://www.youtube.com/watch?v=Y6Ev8GIlbxc&ab_channel=DevoxxPoland