Following the coffe shop analogy in the previous blog post, the coffee shop is booming, and you need to expand your team to handle the growing customer base. But simply adding more baristas isn’t enough. You need a well-organized system to ensure smooth operations, quick recovery from unexpected situations, and efficient storage of customer preferences. This is where replication topologies come in – different ways to structure your team of baristas and order pads (replicas) to achieve specific goals.
The Active/Passive Approach Link to heading
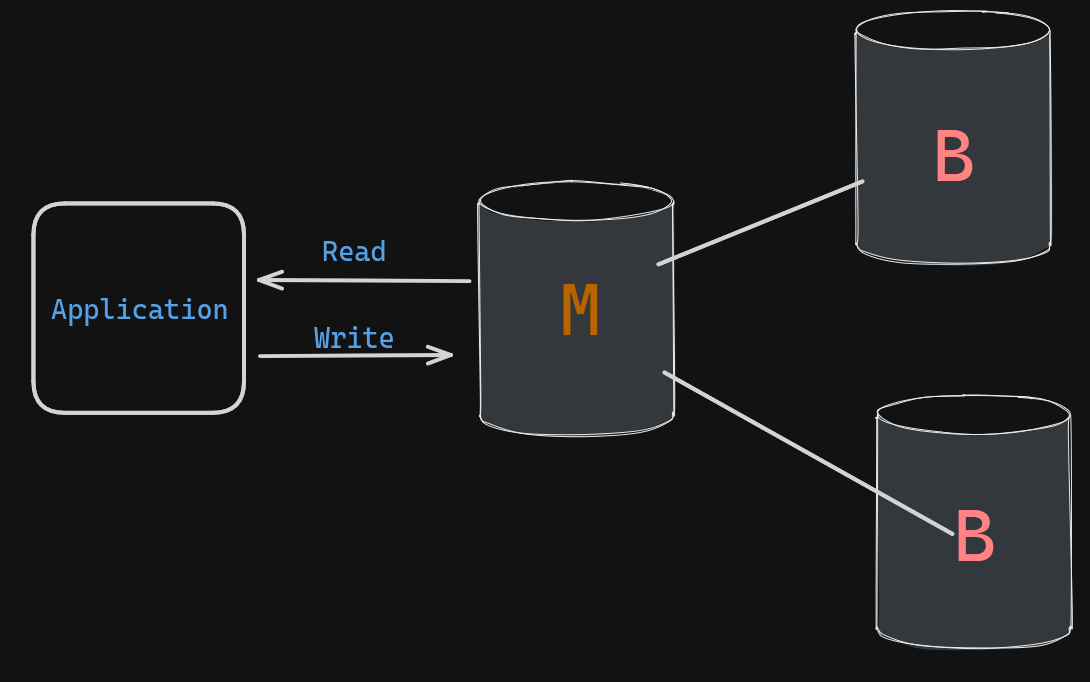 Imagine a single, highly skilled barista (primary server) as the heart of your operation. This barista takes all orders (writes) directly, recording customer preferences (data) on the master order pad. Additionally, you have a few backup baristas (passive replicas) who hold notepads (replicas) containing copies of the master order pad. These backups don’t actively serve customers (don’t handle read traffic).Having those backup baristas (replicas) is crucial. If the main barista gets overwhelmed or spills the order pad (server failure), a backup can take over seamlessly, ensuring customers can still satisfy their coffee cravings (data availability).
Imagine a single, highly skilled barista (primary server) as the heart of your operation. This barista takes all orders (writes) directly, recording customer preferences (data) on the master order pad. Additionally, you have a few backup baristas (passive replicas) who hold notepads (replicas) containing copies of the master order pad. These backups don’t actively serve customers (don’t handle read traffic).Having those backup baristas (replicas) is crucial. If the main barista gets overwhelmed or spills the order pad (server failure), a backup can take over seamlessly, ensuring customers can still satisfy their coffee cravings (data availability).
Since all orders and preference updates (writes) go to the main barista, updates reach the replicas immediately. This ensures all customers get their most fresh preferences.
This approach focuses on accuracy, but it doesn’t horizentally scale (effectively, this is a more reliable monolithic database) for a massive influx of customers. All orders still bottleneck at the single star barista.
Active/Read Pool Link to heading
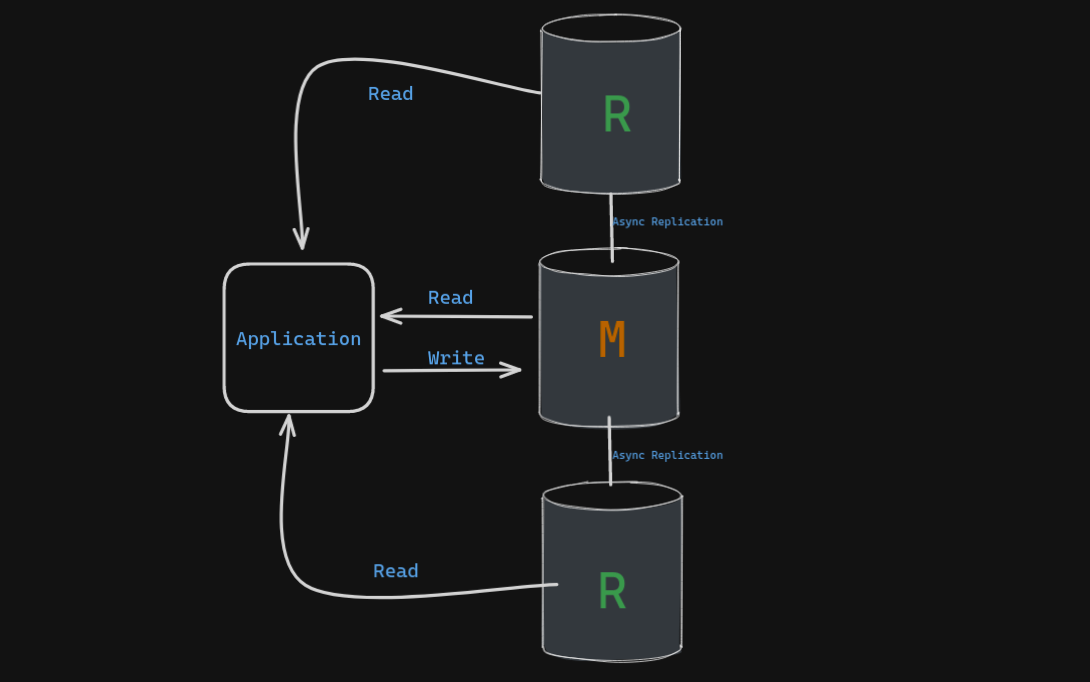 Imagine the star barista (primary server) taking all orders (writes) and recording customer preferences as before. But here’s the twist: you create a dedicated team of baristas (read pool) to handle customer inquiries about drinks (reads). These baristas each have their own updated order pad (replica) containing customer preferences. Customers can approach any barista, including the star barista or someone from the read pool, to ask about the menu (read data) or their past orders stored in the system.
Imagine the star barista (primary server) taking all orders (writes) and recording customer preferences as before. But here’s the twist: you create a dedicated team of baristas (read pool) to handle customer inquiries about drinks (reads). These baristas each have their own updated order pad (replica) containing customer preferences. Customers can approach any barista, including the star barista or someone from the read pool, to ask about the menu (read data) or their past orders stored in the system.
The read pool distributes the workload of answering customer questions about drinks, significantly reducing wait times and keeping customers happy.
As your shop gets even busier, you can easily add more baristas (replicas) to the read pool, effectively scaling your ability to handle customer inquiries.
Considerations:
- Centralized Preference Management: While customers can view their preferences through any barista (read pool), all updates and creations of new preferences must be done with the main barista (primary server).
- Potential for Stale Information: Since customers might interact with the read pool, there’s a chance they might get information about a drink or preference that hasn’t been updated yet on their specific order pad (replica) – a concept called eventual consistency. This is a trade-off for faster service.
- Balancing the Workload: Ideally, the star barista and the baristas in the read pool should have similar skills and knowledge (hardware and software configuration). This ensures a smooth transition if you need to switch to a backup barista (replica).
Why not having multiple masters in a replication topology? Link to heading
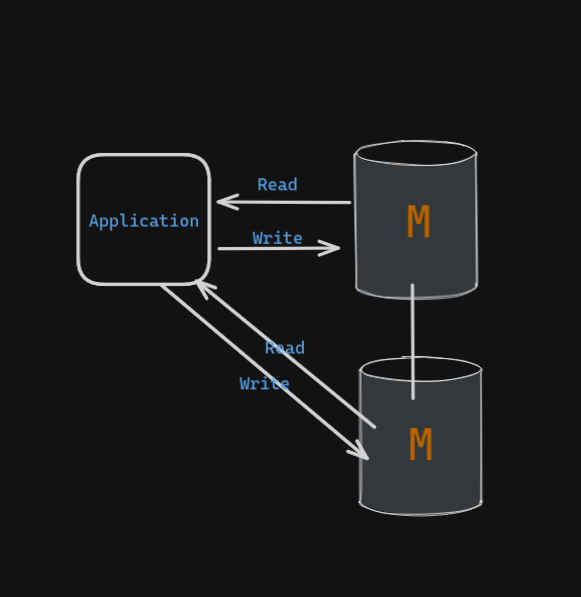
Even though you distribute writes to both masters from your application, each master still needs to process the write itself. On top of that, it needs to handle the additional overhead of replicating the write to the other master(s). This includes writing the replicated statement to its own relay log before execution. At the end, both masters maintain a complete copy of the data.
These factors all contribute to diminishing the scaling benefits of having multiple masters. While you gain some write availability by having redundancy, the trade-offs in terms of complexity, performance overhead, and resource consumption often outweigh the benefits.